Begrüßung¶
Wer bin ich?¶

- Abitur 1998 in Eutin (OH)
- Physikstudium, Promotion 2008
- Postdoc USA
- Scientific Software Developer, QuantumWise (Kopenhagen, DK)
- Wissenschaftler am Europäischen Röntgen-Freie Elektronenlaser (XFEL), Schenefeld bei Hamburg
- Seit 2019 am MPI Evolutionsbiologie in Plön (Wissenschaftliches Rechnen)
Woran forsche ich?¶
- Simulation von Evolutionsprozessen (stochastische Prozesse)
- Anwendung von Hochleistungsrechnern und Hochdurchsatzrechnern in der biologischen Datenverarbeitung
- "Deep Learning" im Bereich der Lebenswissenschaften
Gliederung¶
- Was ist Künstliche Intelligenz
- Maschinelles Lernen mit Neuronalen Netzen: Deep Learning
- Das Neuron als Grundbaustein von Neuronalen Netzen
- Gewichte und Aktivierungsfunktionen
- Kurzreferat Vektoren
- Beispiel: Berechnung einer Ausgleichsgeraden mit einem Neuron
- Tiefe Neuronale Netze
- Parameter und Hyperparameter
- Training Neuronaler Netze
- Overfitting und Dropout
- Genetischer Algorithmus
- Kurzreferat Genetik
- Anwendungsbeispiel: Optimierung eines Neuronalen Netzes mit verteiltem Genetischen Algorithmus
- Zusammenfassung
- Ausblick
Einleitung¶
Künstliche Intelligenz und Turing Test¶
Eine Maschine (Computer) hat den Turing Test bestanden, wenn sie sich in einem Chat nicht von einem menschlichen Gesprächspartner unterscheiden lässt.

Eine Arbeitsdefinition für KI¶
KI umfasst Forschungs- und Technologiebereiche an den Schnittstellen von Computerwissenschaften, Informatik, Kybernetik, Neurowissenschaften, Didaktik und anderen. Im weitesten Sinne bezeichnet KI, die Möglichkeit programmierbaren (Turing) Maschinen, die Rezeption (Erkennung) und anschliessende Verarbeitung von Information mit dem Ziel eines mehr oder minder spezifischen Erkenntnisgewinns im weitesten Sinne beizubringen. Phänologisch ähnelt die Response künstlich intelligenter Systeme intelligentem (menschlichen) Verhalten in Anbetracht derselben oder analoger Daten oder Situationen.
Maschinelles Lernen (ML) ist ein Teilbereich der KI und Deep Learning (DL) widerum ein Teilbereich von ML.

Quelle: https://d25.io/wp-content/uploads/2019/06/Ebenen_KI1-1.jpg
- Traditionelle KI: Deterministisches Modell, das alle Möglichen Situationen und die "richtigen" Antworten darauf beinhaltet.
- Moderne KI: Algorithmus trainiert sich selbst anhand verfügbarer Daten. Ermöglicht durch Big Data.

- Bildverarbeitung (Erkennung 10-fach)

Den Eingangsdaten (Pixelwerte Schwarz-Weiss) werden Label zugeordnet (0,1,2,3,4,5,6,7,8,9)
- Bildverbeitung: Objekterkennung (oder Segmentierung)
 Bildbereichen werden Label (Ja/Nein) zugeordnet.
Bildbereichen werden Label (Ja/Nein) zugeordnet.
- Empfehlungen in Internetsuche, Sozialen Medien

Komplexen Daten (Interpreten, Tonsequenzen, Likes) werden andere komplexe Daten zugeordnet.
- F. Chollet (Deep Learning with Python 2018):

Beaufsichtigtes Lernen mit Neuronalen Netzen (supervised Deep Learning)¶
- Im Gegensatz zu unbeaufsichtigtem DL (Datenrepräsentationen, Verschlüsselung, Kompression)
- Daten bestehen aus Eingangswerten ($X$) und Ausgangswerten ($Y$), sowie der Zuordnung $X\rightarrow Y$
- Z.B. Bild -> Hund oder Katze, Bild -> Zahl 0-9, Lied -> Lied
- Das Neuronale Netz soll diese Zuordnungen lernen um dann zu gegebenen neuen Eingangsdaten $X_\mathrm{neu}$ die richtigen aber bisher unbekannten Label $Y_\mathrm{neu}$ zu finden.
Hund-Katze Beispiel:¶

(Kuenstliche) Neuronale Netze¶
Neuronale Netze als Analogon zu biologischen Neuronalen Netzen¶
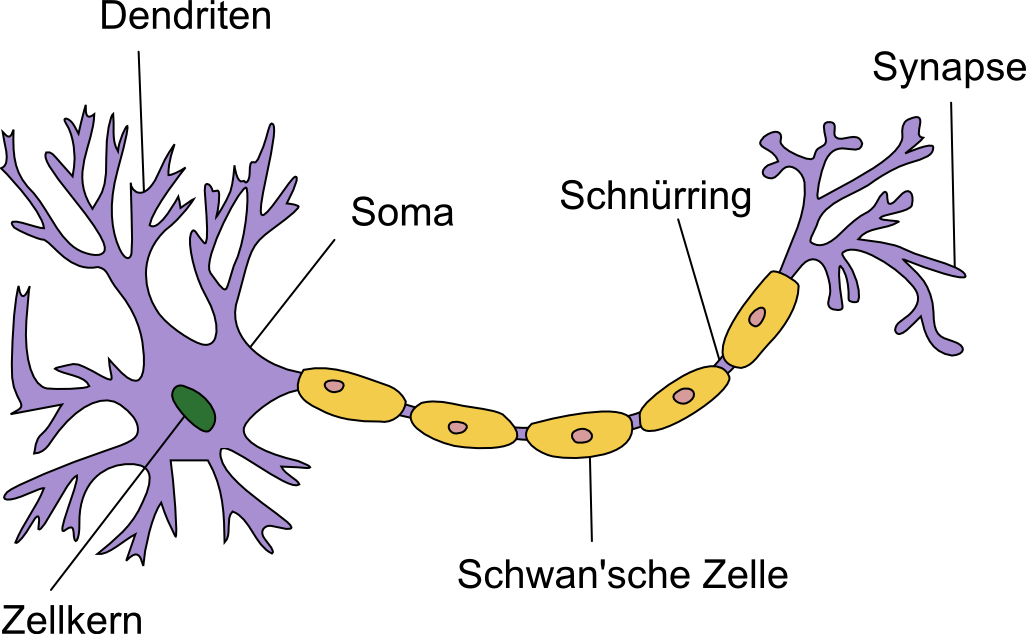
Das Neuron (Nervenzelle)¶
Elektronenmikroskopische Aufnahme einer Nervenzelle

Quelle: https://www.canadiannaturephotographer.com/rberdan_scanning_electron_microscopy2017.html
Das Künstliche Neuron (Perzeptron)¶
- $I_1$: Erstes Eingangssignal (Input)
- $\mathcal{N}$: Neuron
- $O$: Ausgang (Output)
- $I_1$: Erstes Eingangssignal (Input)
- $I_2$: Erstes Eingangssignal (Input)
- $\mathcal{N}$: Neuron
- $O$: Ausgang (Output)
- $I_1$: Erstes Eingangssignal (Input)
- $I_2$: Erstes Eingangssignal (Input)
- $I_3$: Drittes Eingangssignal
- $\ldots$
- $I_N$: Ntes Eingangssignal
- $\mathcal{N}$: Neuron
- $O$: Ausgang (Output)
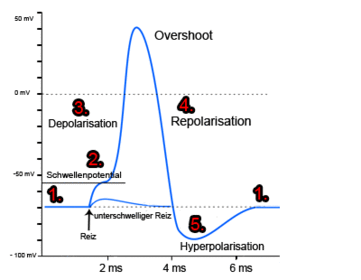
Das Aktionspotenzial¶
- Die Nervenzelle leitet die Erregung erst ab Überschreiten des Schwellenpotentials ab.
- Die Hyperpolarisation sorgt dafür, dass keine Reize "zurück fliessen".
Das Ausgangssignal ist eine Funktion der gewichteten Summe der Eingangssignale¶
Einzelnes Neuron¶

$ O = \mathcal{N}(I_1\cdot w_1)$
Neuron mit zwei Eingängen¶

$O = \mathcal{N}(I_1\cdot w_1 + I_2\cdot w_2)$
Neuron mit N Eingängen¶

$O = \mathcal{N}(I_1\cdot w_1 + I_2\cdot w_2 + ... I_N\cdot w_N)$
$w_1, w_2, \ldots w_N$ sind die Gewichtsfaktoren.
Wir schreiben kurz
$O = \mathcal{N}(\sum_{i=1}^N I_i \cdot w_i)$
Oder noch kürzer als Skalarprodukt (Inneres Produkt) zweier Vektoren:
$O = \mathcal{N}(\vec{I}\cdot \vec w)$
$\vec{I}$ ist der Signalvektor, $\vec{w}$ ist der Gewichtsvektor.
Maschinelles Lernen mit Neuronalen Netzen = Optimierung der Gewichtsfaktoren¶
Die Aktivierungsfunktion $\mathcal{N}$¶
Für die Aktivierungsfunktion haben sich eine Handvoll verschiedener Formen etabliert, hier einige Beispiele:
Sprungfunktion¶

Tanh¶

Relu Funktion¶

Beispiel: "Lernen" einer Ausgleichsgeraden (oder lineare Regression)¶
Ein Team von Biolog*Innen untersucht wie gut sich Bakterien in Abhängigkeit von der Temperatur vermehren.
Dazu erhöhen sie die Temperatur im Labor von 20 auf 30 Grad in 1 Grad Schritten. Nach jeder Einstellung messen Sie die Bakterienzahlen die sich nach 3 Stunden ergibt bei jeweils der gleichen Anfangspopulation. Daraus ergibt sich der Wachstumsfaktor $F$.
Sie messen die folgenden Daten

Aufgabe: Entwickle eine Modell, dass das Bakterienwachstum als Funktion der Temperatur angibt.¶
Wir nutzen hierzu das einfachste Netzwerk, das man sich vorstellen kann: Es besteht aus einem Neuron mit genau einem Eingang und einem Ausgang. Die Aktivierungsfunktion ist die lineare Funktion $F = \mathcal{N}(w\cdot T) = w\cdot T$.

Im Training werden wir den Gewichtsparameter $w$ so einstellen, dass die Vorhersage $\hat N_i = w\cdot T_i$ möglichst gut an den tatsächlich gemessenen Wachstumsfaktoren liegt.
Was bedeutet möglichst gut? Im Idealfall sollte die Differenz $\hat N_i - N_i$ für alle i verschwinden, dann wäre das Modell perfekt.
Andererseits wissen wir, dass Messdaten immer mit einer Unsicherheit versehen sind. Hätten wir ein Modell, das perfekt unsere Daten wiedergibt, so würde dasselbe Modell bei einer wiederholten Messung aller Wahrscheinlichkeit nach sehr schlecht abschneiden. Wir brauchen also ein Modell, das im Mittel die Daten gut annähert. Und wir benötigen ein Mass für die statistische Abweichung zwischen unserem Modell und den Daten. Dieses Mass der Abweichung gilt es dann zu minimieren.
Ein gebräuchliches Mass für die Abweichung zwischen einem Modell und Daten ist die mittlere quadratische Abweichung. Sie lautet $V = \sum_{i=1}^{N} (\hat F_i - F_i)^2$.
In unserem Fall (11 Messwerte, also $N=11$) bedeuted dies: $V =(\hat F_1 - F_1)^2 \ \ \ \ \ + \ \ (\hat F_2 - F_2)^2 + (\hat F_3 - F_3)^2 + \ldots + (\hat F_{11} - F_{11})^2 $ $\ \ \ = (w\cdot T_1 - F_1)^2 + (w\cdot T_2 - F_2)^2 + (w\cdot T_3 - F_3)^2 + \ldots + (w\cdot T_{11} - F_{11})^2$ $\ \ \ = \sum_{i=1}^{11} (w\cdot T_i - F_i)^2$
Diesen Ausdruck wollen wir nun minimieren.
Das Extremum einer Funktion ist durch das Nullwerden der ersten Ableitung gegeben:
$ \frac{dV}{dw} = V' = 0 $
$ \ \ \ = \left[ \sum_{i=1}^{11} (w\cdot T_i - F_i)^2\right]'$
$ \ \ \ = \sum_{i=1}^{11} 2\cdot(w\cdot T_i - F_i)\cdot T_i $
$ \ \ \ = 2\cdot w\cdot\sum_{i=1}^{11} T_i^2 - 2\cdot\sum_{i=1}^{11} T_i\cdot F_i = 0$
$ 2\cdot w\cdot\sum_{i=1}^{11} T_i^2 = 2\cdot\sum_{i=1}^{11} T_i\cdot F_i $
$ w\cdot\sum_{i=1}^{11} T_i^2 = \sum_{i=1}^{11} T_i\cdot F_i $
$ w = \frac{\sum_{i=1}^{11} T_i\cdot F_i}{\sum_{i=1}^{11} T_i^2}$
Daraus ergibt sich das optimale Gewicht $w$. Wir können es nun direkt aus den Daten bestimmen:
Nun können wir zu den vermessenen Temperaturen die Vorhersagen unseres Modells berechnen und mit den tatsächlich gemessenen Werten vergleichen:

Wir sehen, dass unser Modell eine Gerade ergibt, die im Mittel durch die Messwerte hindurchgeht. Dieses Modell wird auch Lineare Regression genannt und ist ein wichtiges Werkzeug der Datenanalyse.
Wir haben gesehen, dass wir Lineare Regression auch als einfache Anwendung von Maschinellem Lernen verstehen können. Dabei lernt das Modell einen einzigen Gewichtsfaktor, $w$. In diesem einfachen Fall können wir $w$ analytisch (also ohne Computerrechnung) bestimmen. Dies ist aber die Ausnahme. In den allermeisten Anwendungsfällen für maschinelles Lernen müssen die Gewichtfaktoren in einem numerischen Algorithmus optimiert werden. Dieser Algorithmus besteht aus den folgenden Elementen:
- Initialisierung aller Gewichte $w_i^0$ mit Zufallszahlen
- Berechnung der Modellvorhersage
- Wie nah oder fern ist die Modellvorhersage von den Trainingsdaten?
- Korrektur der Gewichte $w_i^0 \rightarrow w_i^1$
- Berechnung der Modellvorhersage ...
Der Trainingsalgorithmus¶

Wie finde ich das Minimum der Funktion $D(\vec w)$?¶
In einer Dimension¶
Auf der Tafel
In zwei Dimensionen (z.B. ein Neuron mit zwei Eingängen oder zwei Neuronen mit jeweils einem Eingang.)¶
In zwei Dimensionen können wir die Funktion $D(\vec w) = D(w_x, w_y)$ als Höhenkarte interpretieren.


Ein Beispiel für ein künstliches Neuronales Netz mit 2 versteckten Schichten¶
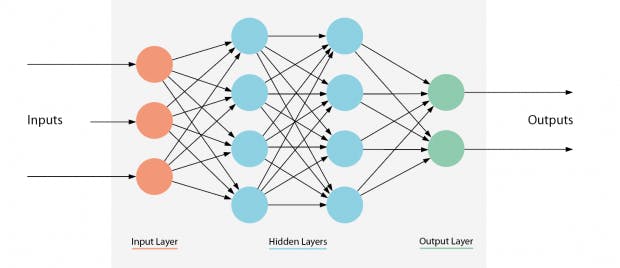
Credits: https://t3n.de/magazin/frameworks-fuer-machine-learning-gelingt-einstieg-247180/
In höheren Dimensionen?¶
In produktiv genutzten NNen ist die Anzahl der Gewichtsparamer und damit die Dimension der Landschaft sehr gross. Hier kann man das Problem nicht mehr so einfach veranschaulichen, aber die Mathematik ist die gleiche: Das Minimum von $D(\vec w)$ wird gesucht, in dem man ausgehend von einem zufällig gewählten Anfangspunkt immer dem steilsten Anstieg in umgekehrter Richtung folgt. Dabei ist das Problem der lokalen Senken zu beachten. Dies kann dadurch abgemildert werden, dass man Sprünge in Richtung der positiven Steigung von Zeit zu Zeit zulässt.
Die Steigung der "Landschaft" lässt sich bei sehr vielen Dimensionen nicht mehr effektiv berechnen. Man geht daher zu einer Methode über, die sich Methode des "stochastische Gradientenabstiegs" (stochastic gradient descent, sgd) nennt. Dabei werden widerum zufällig einige Gewichte ausgesucht und die Steigung nur mit diesen berechnet. Ausserdem werden die Trainingsdaten in sog. Batches unterteilt und die Steigung mit jeweils einem Batch berechnet. Eine vollständige Iteration, also Berechnung des Ausgangssignals, Vergleich mit den Trainingslabeln, Abstandsmetrik, Steigung, Korrektur der Gewichte für alle Batches nennt man eine Trainingsepoche.
Training, Validierung, Testen¶
Wie bereits angedeutet, ist es wichtig beim eine Maschine nicht zu genau zu trainieren, da sie sonst zwar die trainierten Daten sehr genau kennt und richtig widergibt, aber bei der Anwendung auf neue Daten eher schlecht abschneidet. Diese Tatsache wird Overfitting genannt und ist das zentrale Problem der KI.
Um das Problem des Overfitting wenn nicht zu lösen, dann doch zumindest zu erkennen, hat sich folgender Arbeitsablauf beim Training eines KI Algorithmus etabliert. Dabei trennt man von den zur Verfügung stehenden Daten zunächst in einen Testdatensatz ab. Den Testdatensatz lässt man während der gesamten Trainingsphase unangetastet und benutzt ihn erst als allerletztes um zu evaluieren, wie gut (oder schlecht) der trainierte Algorithmus abschneidet, wenn er auf Daten angewendet wird, die er zuvor noch nie gesehen hat.
Die übrigen Daten werden in einen Trainings- und einen Validierungsdatensatz aufgeteilt. Mit den Trainingsdaten wird das Netzwerk trainiert, also iterativ die Gewichte $w$ eingestellt bis der Unterschied zwischen Ausgang und den Labeln des Testdatensatzes minimiert ist. Mit den Validierungdaten wird nach jeder Trainingsepoche (=eine Iteration über alle Trainingsdaten) validiert wie gut das Netzwerk auf neuen Daten abschneidet.

Als Kriterium wie gut das Netzwerk auf neuen Daten arbeitet, kann man z.B. die Verlustfunktion, also den Abstand zwischen Netzwerkausgang und Trainingslabeln gegen die Anzahl der Trainingsdurchläufe grafisch darstellen:

Wie erwartet sinkt der Abstand zwischen Ausgang und Trainingslabeln mit jeder Iteration. Angewendet auf die Validierungsdaten zeigt sich aber bereits nach 5 Epochen, dass das Netzwerk zu gut an die Trainingsdaten angepasst ist und neue Daten nicht versteht.
In diesem Beispiel würde man das Netzwerk nur maximal 5 Epochen lang trainieren, um Overfitting zu vermeiden.
Hier haben wir das erste Beispiel dafür, dass neben den Gewichten des Netzwerks noch andere Eigenschaften angepasst oder optimiert werden müssen, hier nämlich die Anzahl der Trainingsepochen. Zur Abgrenzung zu den Netzwerkparametern (bisher Gewichte genannt), werden diese anderen Eigenschaften Hyperparameter genannt. Die Optimierung der Hyperparameter ist ein eigenes Forschungsgebiet mit verschiedenen Ansätzen und Methoden. Im zweiten Teil der Unterrichtseinheit werden wir eine Methode, den Genetischen Algorithmus kennenlernen und selbst anwenden.
Dropout als Strategie zur Vermeidung von Overfitting¶
- Eine Dropout Schicht im Netzwerk sortiert zufällig ausgewählte Daten aus. Dadurch sieht der Trainingsalgorithmus bei jeder Iteration einen anderen Teil der Trainingsdaten. Der Algorithmus hat weniger Möglichkeit, sich an die Trainingsdaten zu gewöhnen. Der relative Anteil aussortierter Daten ist die sog. Dropout Rate.


Credits: F. Chollet, Deep Learning with Python, 2018)
Anwendungsbeispiel: Automatisches Erkennen handgeschriebener Zahlen: Der MNIST Datensatz¶
Eingangsdaten: Bilder von 28x28 Pixeln, Schwarz-Weiss Ausgangsschicht: 10 Kanäle
Genetischer Algorithmus¶
-> Kurzreferat Genetik
Genotyp und Phänotyp¶
- Der Genotyp (das Genom) bestimmt die Bandbreite, innerhalb derer sich der Phänotyp ausbilden kann.
- Keine Eins-zu-Eins Beziehung sondern komplexes Netzwerk aus kodierenden und regulativen Sequenzen. Ausserdem Umwelteinflüsse, Prägung während der Entwicklung, Epigenetische Faktoren.
- Aktives Forschungsgebiet
- In neuerer Zeit vermehrt Anwendungen von Neuronalen Netzen zur Auflösung der Genotyp-Phänotyp Beziehung
Genetischer Algorithmus¶

Quelle: Dissertation Andreas Teckentrup 2000 (Uni Erlangen). Online https://www2.chemie.uni-erlangen.de/services/dissonline/data/dissertation/Andreas_Teckentrup/html/ (Besucht am 24.11.2020)
Uebertragung auf Neuronale Netze¶
- Ein NN Chromosom hat folgende Gene:
- Anzahl der Netzschichten
- Typ der Schicht (Dense, Dropout)
- Anzahl der Neuronen
- Batchgröße
- Dropout Rate
- ...
- Während der Lernphase bildet das NN einen Phänotyp heraus (Optimieren der Gewichte bei vorgegebener Netzwerktopologie)
- Die Validierung des trainierten NNs ordnet dem Phänotyp und damit dem Chromosom einen Score zu

- Die NNe mit den besten Scores und ein paar schlechtere werden als Eltern der nächsten Generation ausgewählt.
- Durch Crossover und Mutation wird die nächste Generation gebildet.
- Die neue Generation wird trainiert und gescort.
1. Generation¶

Selektion (nach Performance Score)¶

Selektion nach Zufall¶

Ausgangspunkt der nächsten Generation¶

Kopie¶

Kreuzung (engl. Crossover)¶

Mutation¶

Konstruktion der nächsten Generation¶

Konstruktion der neuen NNe, Training, Validierung, ...¶

Genetischer Algorithmus im Ueberblick¶

Zusammenfassung¶
- Maschinelles Lernen mit neuronalen Netzen macht aus grossen Datenmengen (Big Data) aussagekräftige Modelle.
- Ein neuronales Netz extrahiert aus den Daten die zugrundeliegenden Strukturen und Zusammenhänge.
- Das Training einen neuronalen Netzes ist ein hochdimensionales Optimierungsproblem.
- Netzparameter (Gewichte)
- Hyperparameter:
- Topologie
- Aktivierungsfunktion
- Optimierungsalgorithmus
- Batch Size
- Dropout rate
- Loss Funktion
- Training der Netzparameter: Gradientenmethode, Backpropagation
- Problem: Overfitting
- Dropout als Gegenmittel
- Hyperparametertraining: Aktives Forschungsgebiet, bisher kein Goldstandard gefunden.
- Hier: Optimierung der Hyperparameter mit Genetischem Algorithmus
Ausblick¶
- Chancen und Risiken der KI
- Wer mitreden will sollte wissen worum es geht und wie es funktioniert
- Interessantes (weil interdisziplinäres) Forschungsfeld
- Generelle KI ist (noch) weit weg.
- Paradigmenwechsel:
- Optimierung, gestelltes Problem soll möglichst gut gelöst werden (Konvergenz)
- <-> Evolution: Artenvielfalt, Divergenz. Wen oder was optimiert die Evolution?
- Erkundung neuer Möglichkeiten (Divergenz)
- Belohne Neuigkeit, nicht Nähe zum althergebrachten -> Vermeidung lokaler Minima
- Suche nach einem immer weiter divergierenden Algorithmus, der immer wieder neue aber gute Lösungen findet.
- PicBreeder: http://picbreeder.org